Data Orchestration Service
The Data Orchestration Service handles query execution, data catalog management, schema discovery, and data lineage tracking across multiple data sources.
Quick Navigation
Overview
The Data Orchestration Service is responsible for:
- Executing queries and data plans across multiple data sources
- Managing the data catalog with schema discovery and metadata
- Tracking data lineage (upstream and downstream dependencies)
- Providing AI context for query generation
- Managing connectors for 30+ data source types
Service Architecture Flow Diagram
View Flow Diagram
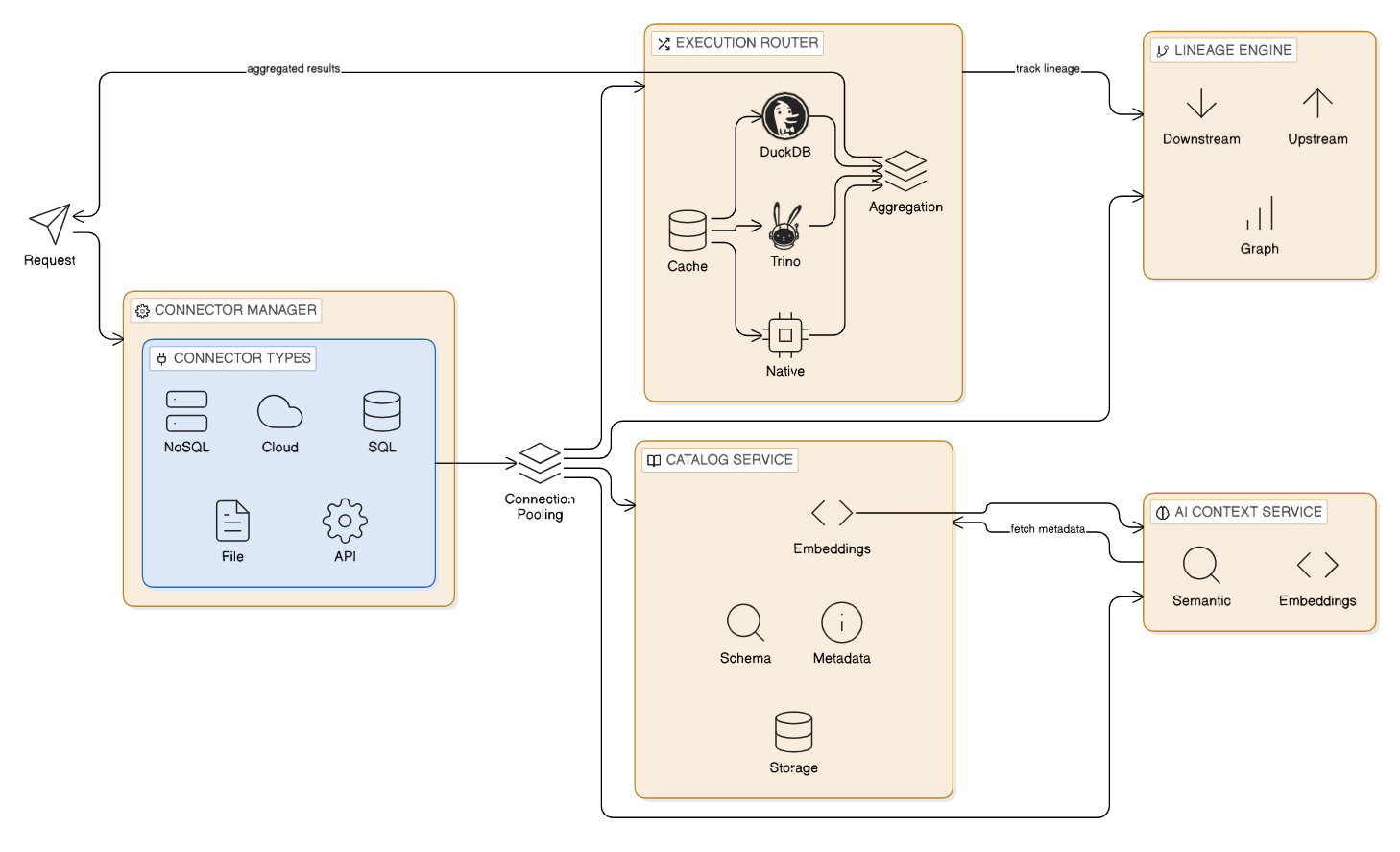
Data Orchestration Flow Overview:
This flow diagram illustrates the complete data orchestration workflow from connector management through query execution and lineage tracking. It demonstrates how data sources are connected, schemas are discovered, queries are executed, and data lineage is tracked.
Key Flow Components:
- Connector Management: Routes requests to appropriate connector types (SQL, NoSQL, Cloud, File, API)
- Connection Pooling: Establishes and manages connections to data sources
- Catalog Service: Discovers schemas, extracts metadata, generates embeddings
- Execution Router: Routes queries to DuckDB, Trino, or native execution engines
- Query Execution: Executes queries with caching and result aggregation
- Lineage Engine: Tracks upstream and downstream data relationships
- AI Context Service: Provides semantic search via embeddings for query generation
Base Path
All endpoints are prefixed with /api/v1 or root / for health checks.
Base URL: http://data-orchestration:8000 (internal) or http://localhost:8000 (development)
Authentication
The service uses header-based authentication:
X-Org-ID: <organization_id>
X-User-ID: <user_id> (optional)
Note: The service accepts user_context in request bodies for stateless execution, allowing the main API to pass decrypted credentials at runtime.
Endpoints
Health & Status
| Method | Endpoint | Description |
|---|---|---|
| GET | /health | Check service health |
| GET | /metrics | Get system metrics |
Execution
| Method | Endpoint | Description |
|---|---|---|
| POST | /execute | Execute a data plan |
| POST | /query | Execute a simple SQL query |
Connectors
| Method | Endpoint | Description |
|---|---|---|
| GET | /connectors | List available connectors |
| GET | /connectors/{connector_id} | Get connector details |
| POST | /connections/test | Test connection to a data source |
Catalog
| Method | Endpoint | Description |
|---|---|---|
| POST | /catalog | Catalog a data source |
| GET | /catalog/tables | List tables in catalog |
| GET | /catalog/schemas | Get hierarchical catalog structure |
| POST | /catalog/search | Search catalog by text |
| GET | /catalog/tables/{table_id} | Get table details including columns |
| POST | /catalog/ai-context | Get catalog context for AI query generation |
Lineage
| Method | Endpoint | Description |
|---|---|---|
| GET | /lineage/upstream/{table_id} | Get upstream lineage for a table |
| GET | /lineage/downstream/{table_id} | Get downstream lineage for a table |
| GET | /lineage/graph | Get complete lineage graph |
Schema Discovery
| Method | Endpoint | Description |
|---|---|---|
| GET | /schema/{data_source_id} | Discover schema for a data source |
Total: 17 endpoints
Internal Notes
- Service accepts stateless execution with
data_source_configsin request body - Supports multiple compute engines (DuckDB, Trino)
- Uses vector database (Qdrant/Pinecone) for semantic catalog search
- Catalog supports embeddings for AI-powered table discovery
- Lineage tracking provides data dependency graphs
- All endpoints are fully implemented