Decision Intelligence (DIA) Overview
This page provides the exhaustive technical specification and architectural breakdown for the Decision Intelligence Agent (DIA), the primary active monitoring engine of the RiverGen ecosystem.
Overview
Decision Intelligence (DIA) operates as the "Decision Brain" within the RiverGen intelligence layer. It is an active monitoring system that aggregates multi-agent telemetry and applies probabilistic machine learning models to execute autonomous platform corrections.
The service transforms passive observability data into actionable triggers. It ensures that the platform architecture remains optimized and secure by making sub-10ms decisions governed by natural language guidelines and deterministic safety boundaries.
Use Cases
DIA is designed to handle high-velocity decision-making where human-in-the-loop intervention is impractical due to speed or scale requirements.
- Autonomous Resource Scaling: Identifying capacity bottlenecks across agent nodes and triggering automated scaling events based on predictive usage.
- Proactive Threat Mitigation: Detecting anomalous behavioral patterns in platform telemetry and automatically isolating compromised connectors or users.
- Workload Optimization: Dynamically re-routing queries and storage tasks based on real-time latency and compute cost estimations.
- Adaptive Execution Policy: Applying context-aware governance rules that adjust based on the sensitivity of the data being accessed in a live loop.
Inputs: Agent Telemetry
The DIA service ingests high-velocity metadata streams from various platform agents. These inputs are collapsed into standardized feature vectors before being processed.
| Field | Type | Description |
|---|---|---|
agent_id | uuid | Unique identifier for the reporting platform node. |
cpu_usage | float | Percentage of CPU utilization at the time of the event. |
latency_ms | integer | Current request processing time in milliseconds. |
error_rate | float | Percentage of failed operations within the current window. |
custom_metadata | object | Domain-specific telemetry fields for specialized decision models. |
Outputs: Decision Payloads
The service returns a DecisionResponse that includes the final action, mathematical certainty, and an exhaustive reasoning log explaining the intelligence path.
| Field | Type | Example Value |
|---|---|---|
decision_id | uuid | Unique identifier for the audit trail record. |
decision_value | enum | The final concluded action (e.g., high_priority, isolate). |
confidence | float | Mathematical probability of the ML model's prediction (0.0 to 1.0). |
reasoning_log | string | Narrative explanation of the applied rules and model logic. |
execution_status | enum | Status of the dispatched correction action via OSA. |
System Architecture
The DIA architecture implements a three-layer pipeline to ensure that every decision is concurrently data-driven and policy-aligned.
- System Architecture
- DIA vs Model Studio
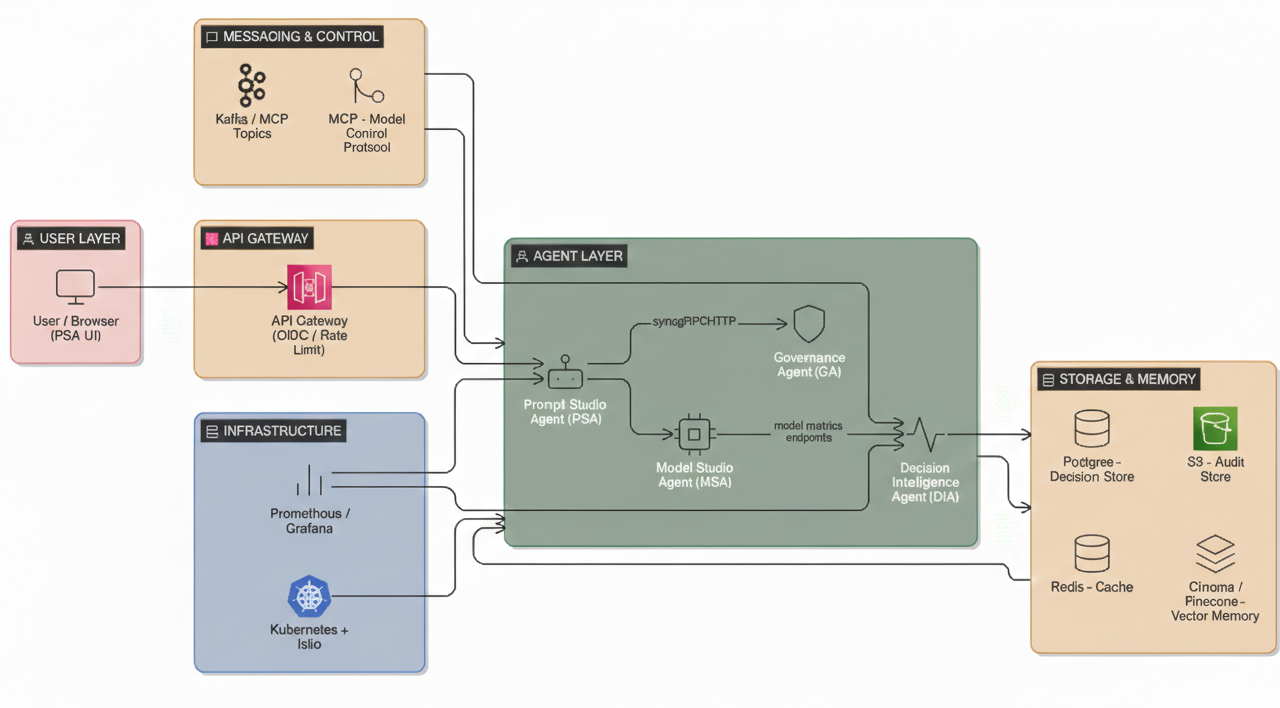
The system architecture utilizes hot-loaded in-memory models to achieve sub-millisecond inference times, with a dedicated post-processing layer for guideline fulfillment.
| Aspect | Model Studio | Decision Intelligence (DIA) |
|---|---|---|
| Primary Function | Train ML models | Execute ML-based decisions |
| Ingress Pattern | Batch/Stream datastores | Live Agent telemetry |
| Outgress Pattern | Artifact persistence | Autonomous Action dispatch |
| State Layer | File System + DB | In-Memory Registry + DB |
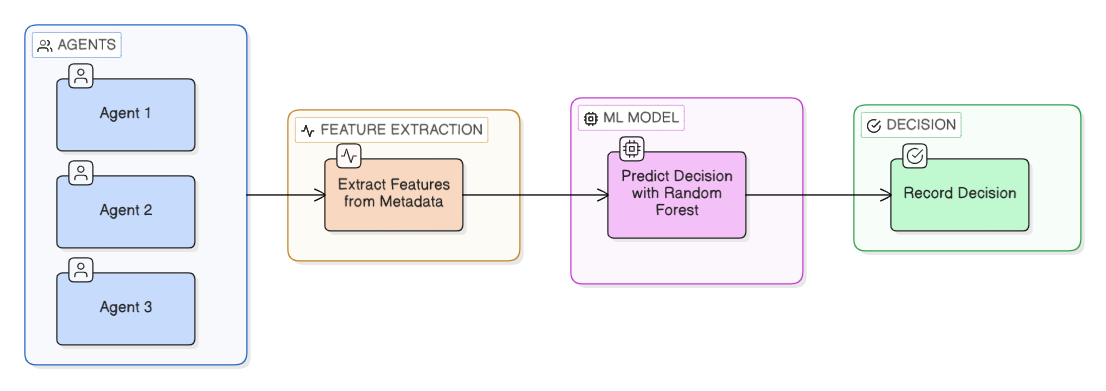
Model Behavior: The Decision Pipeline
DIA operates a sequential three-phase engine that preserves safety while maximizing autonomous throughput.
- Feature Extraction: Raw agent metadata is ingested and collapsed into standardized numeric vectors, removing noise from high-velocity telemetry streams.
- ML Inference: Metadata vectors are passed through the in-memory registry (Random Forest or XGBoost) to generate a probabilistic decision value.
- Guideline Refinement: The raw ML output is passed to the
apply_prompt_guidelinesservice, which applies deterministic rules and safety overrides to prevent hallucinations.
Configuration and Rule Guidelines
Decision behavior is governed by a hierarchical rule system that provides human-level guard rails over autonomous model predictions.
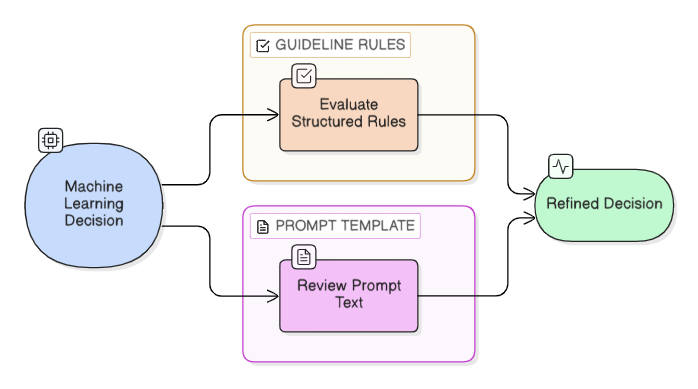
- Safety Layering: If a model makes a low-confidence or non-compliant prediction, the rule framework forces an override to the safest known action.
- Dynamic Guidelines: Logic can be updated in real-time via the Registry API without requiring a service restart or model retraining.
Integration Guide: The /decide API
External services and agents integrate with DIA through a high-performance RESTful interface.
1. Requesting a Decision
Clients POST encrypted telemetry payloads to the /decide endpoint. The service handles the feature extraction and model inference synchronously.
curl -X POST https://api.rivergen.local/dia/v1/decide \
-H "Content-Type: application/json" \
-d '{"agent_id": "99ea", "metadata": {"cpu": 0.85, "io": 120}}'
2. Handling the Response
The returned payload includes the recommended action and the telemetry ID for distributed tracing across the platform.
{
"decision": "SCALING_REQUIRED",
"confidence": 0.94,
"telemetry_id": "exec_552"
}
Cost and Performance
- Inference Speed: Core ML predictions resolve in under 10 milliseconds due to the in-memory registry architecture.
- Resource Efficiency: DIA uses localized feature extraction to limit the bandwidth consumed by high-frequency telemetry streams.
- Scalability: horizontal scaling of API nodes allows DIA to handle over 10,000 decision requests per second in clustered environments.
Limitations and Known Issues
- Cold Start Latency: The first decision request after a model update may experience a 500ms delay as the artifact is hot-loaded into the registry.
- Feature Sparsity: Predictions may degrade if agents provide incomplete metadata schemas that do not match the training requirements.
- Rule Conflict Resolution: When multiple guidelines provide conflicting overrides, the system defaults to the most conservative (lowest-risk) action.