Backend Architecture and APIs
Page Outline
This document provides the exhaustive technical specification for the Prompt Studio (PSA) backend infrastructure, including service layering, database schemas, and API definitions.
Overview
The PSA backend is architected as a modular system that bridges the gap between natural language processing and technical platform execution. It operates through the Top-Level Orchestrator (TLO) Gateway to ensure secure and validated data operations.
The system utilizes a three-channel frontend architecture. All API requests route through the TLO Gateway via HTTP, file operations use the Storage Gateway, and real-time execution progress is streamed via WebSocket.
Use Cases
The backend architecture supports various high-concurrency and mission-critical engineering workflows.
- Dynamic Intent Routing: Automatically dispatching requests to specialized domain agents based on real-time reasoning.
- Asynchronous Execution: Utilizing Temporal workflows to manage long-running AI and data query operations safely.
- Real-Time Monitoring: Streaming detailed execution traces and progress percentages to frontend clients via WebSocket.
- Policy Enforcement: Intercepting every tool call to validate permissions against RBAC and RLS rules before routing to target services.
Inputs: API Contract and Schemas
PSA accepts structured requests via the TLO Gateway and the platform backend. The following Pydantic schemas define the communication contract.
class PromptExecuteRequest(BaseModel):
prompt_text: str # User instruction
workspace_id: Optional[int]
selected_data_source_ids: List[int] # Target data sources
selected_schema_names: Optional[List[str]] # Schema filter
save_prompt: bool = False # Persist after execution
ai_model: Optional[str] # Override default model
tags: Optional[List[str]] # Categorization tags
Outputs: Execution Payloads
The service returns a comprehensive execution status that includes AI metadata and performance metrics.
class PromptExecutionResponse(BaseModel):
execution_id: Optional[int]
status: str # pending | completed | failed
ai_processing_status: Optional[str] # processing tracking
query_execution_status: Optional[str]# data layer tracking
started_at: Optional[datetime]
completed_at: Optional[datetime]
total_duration_ms: Optional[int]
generated_query_text: Optional[str]
rows_returned: Optional[int]
result_preview: Optional[List[Dict[str, Any]]]
ai_metadata: Optional[AIMetadataResponse]
progress_percentage: Optional[int]
Model Behavior: Dynamic Orchestration
The TLO Gateway has transitioned from static routing to a dynamic orchestration model driven by the PSA agentic loop.
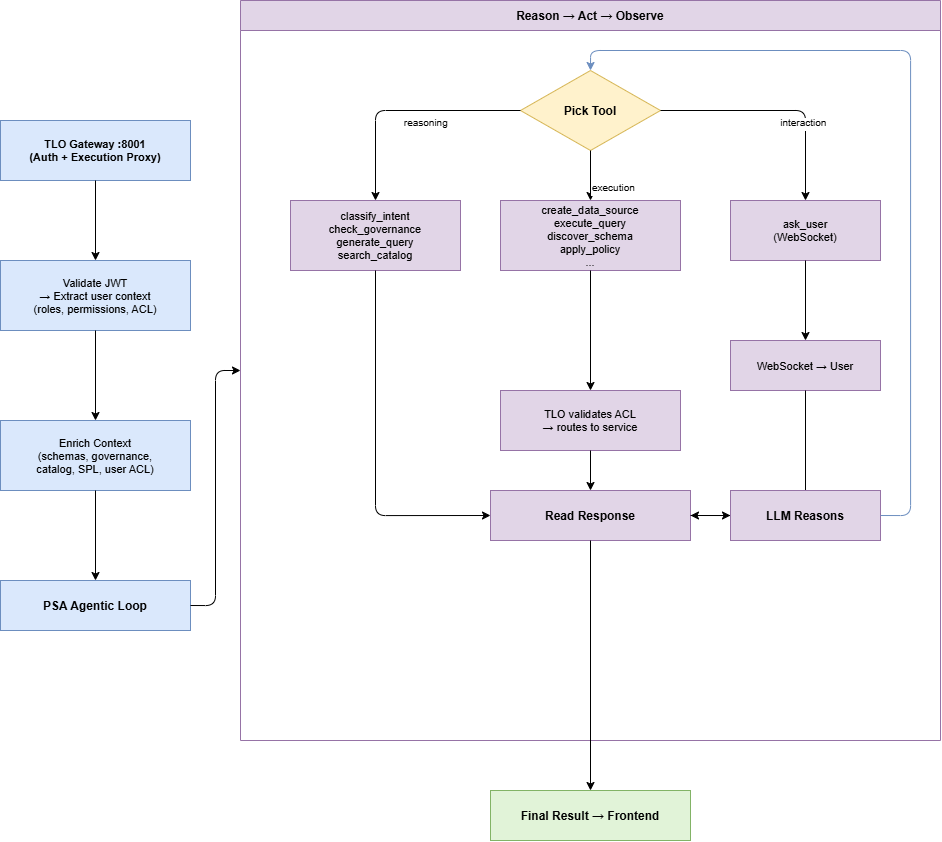
- Agent Initiation: PSA receives the prompt and enters the Reason-Act-Observe loop.
- Tool Proxying: When PSA calls an execution tool, the TLO Gateway intercepts the call.
- ACL Validation: TLO validates the user's permission (e.g.,
data_source:query) before proceeding. - Internal Routing: Authorized calls are routed to downstream services (Backend, Data Orchestration) with an internal identity header.
Configuration Options: TLO and Workflow
Orchestration behavior is tuned via the TLO configuration layer to manage timeouts and retry strategies for AI operations.
| Parameter | Value | Description |
|---|---|---|
psa_timeout_seconds | 30 | Execution ceiling for the agentic reasoning loop. |
psa_retry_count | 3 | Number of automatic retries for failed tool calls. |
psa_backoff_coeff | 2.0 | Exponential multiplier for retry intervals. |
tlo_max_matched_tables | 10 | Maximum entities provided in the RiverSemantic context. |
ws_ping_interval | 30 | Frequency of WebSocket heartbeat signals in seconds. |
Integration Guide: WebSocket Lifecycle
WebSocket communication is critical for handling real-time progress and bidirectional interaction during the agentic loop.
Cost and Performance
The backend optimizes performance through asynchronous task handling and efficient context management.
- Temporal Orchestration: Ensures reliability and state persistence for long-running multi-source joins.
- WebSocket Streaming: Reduces perceived latency by providing instantaneous feedback on internal reasoning steps.
- Provider Caching: Caches schema lookups and intent classifications to reduce redundant LLM calls and associated costs.
Limitations and System Constraints
- Single Gateway Routing: All execution-tier tool calls must pass through TLO; direct backend-to-source calls are prohibited in the agentic model.
- Workflow State Limits: Temporal workflow histories are optimized to prevent performance degradation for extremely long-running agents.
- WebSocket Concurrency: Limits individual execution IDs to 5 concurrent WebSocket connections to prevent resource exhaustion.
Database and Service Model
Database Schemas (SQL)
The PSA backend utilizes several relational tables to track prompts, executions, and analytics.
Prompts Table
CREATE TABLE prompts (
id SERIAL PRIMARY KEY,
organization_id INTEGER NOT NULL,
prompt_text TEXT NOT NULL,
ai_model_used VARCHAR(255),
status VARCHAR(50) DEFAULT 'draft',
created_at TIMESTAMP DEFAULT NOW(),
deleted_at TIMESTAMP -- soft delete
);
Executions Table
CREATE TABLE prompt_executions (
id SERIAL PRIMARY KEY,
prompt_id INTEGER REFERENCES prompts(id),
status VARCHAR(50),
started_at TIMESTAMP,
total_duration_ms INTEGER,
generated_query_text TEXT,
rows_returned INTEGER,
result_preview JSON,
error_message TEXT
);
Directory Structure
The repository follows a clean-architecture pattern, separating service logic from API routing and workflow orchestration.
rgen-repo-backend/rgen-backend/
├── app/
│ ├── main.py # FastAPI entry
│ └── platform/
│ ├── routers/prompt_studio.py # API Endpoints
│ ├── services/prompt_service.py # Business Logic
│ ├── models/prompts.py # ORM Models
│ └── schemas/prompts.py # Pydantic Schemas
└── services/tlo_gateway/
├── api/routes.py # TLO Routes
└── workflows/psa_workflow.py # Temporal Workflows