Model Studio Technical Implementation
Page Outline
This document provides a deep-dive into the engineering principles, service mesh patterns, and data pipelines that power RiverGen Model Studio (v1.0.2).
Architectural Blueprint
The Model Studio implementation follows a strict Layered Service Mesh pattern. Every request is authenticated via internal mTLS and logged for auditing within the RiverGen master telemetry system.
Service Mesh Topology
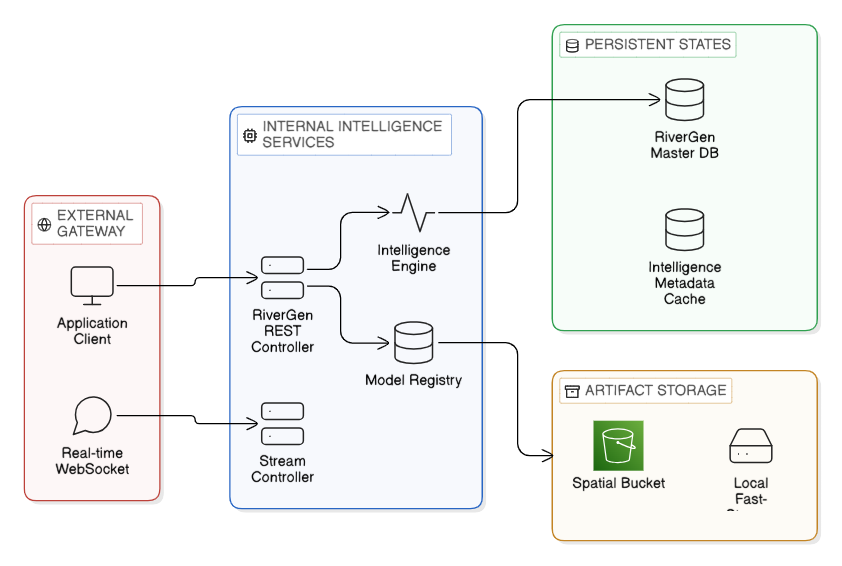
View Mermaid Source Code
Service Mesh Explanation
The Model Studio service mesh implements a microservices topology with clear separation between external gateways, internal services, and persistence layers:
External Gateway Layer: Provides two entry points for client interactions:
- Application Client: Traditional REST API access for synchronous operations (submit tasks, query status, make predictions)
- Real-time WebSocket: Streaming interface for live progress updates during long-running training jobs
Internal Intelligence Services: The core processing layer consists of four specialized services:
- RiverGen REST Controller: Routes HTTP requests to appropriate internal services, handles authentication and request validation
- Stream Controller: Manages WebSocket connections, broadcasting training progress and system events to connected clients
- Intelligence Engine (AutoML): The computational core that executes the ML pipeline—data analysis, preprocessing, training, and evaluation
- Model Registry: Manages the lifecycle of model artifacts, including storage, versioning, and retrieval
Persistent States: Dual-layer persistence strategy optimizes for different access patterns:
- RiverGen Master DB (PostgreSQL): Stores all structured metadata (task intents, training jobs, model registry, performance metrics). Optimized for complex queries and transactional consistency.
- Intelligence Metadata Cache (Redis): High-speed cache for frequently accessed metadata and session state. Reduces database load for hot-path operations.
Artifact Storage: Binary model artifacts are stored in a tiered storage system:
- Local Fast-Storage (FS): SSD-based local storage for active models requiring sub-millisecond access times
- Spatial Bucket (S3): Cloud object storage for long-term archival, model versioning, and disaster recovery
Key Architectural Patterns:
- Service Isolation: Each service has a single, well-defined responsibility
- Async Communication: Long-running operations use background workers to prevent blocking
- Caching Strategy: Hot models cached in Redis, warm models on local FS, cold models in S3
- mTLS Security: All internal service-to-service communication uses mutual TLS authentication
Service Implementation
1. API Gateway (FastAPI)
Source Path: src/api/routes/rivergen_ai.py
The Gateway implements a strict validation pattern using Pydantic, ensuring that all Intelligence Tasks conform to the 1.0.2 specification before they reach the engine.
# Specific Implementation for RiverGen 1.0.2
@router.post("/task-intent", status_code=201)
async def submit_rivergen_task(task: RiverGenTaskRequest, db: Session):
"""
Submits a new intelligence task to the RiverGen ecosystem.
Validates spatial coordinates and platform agent compatibility.
"""
# 1.0.2 Strict Validation
if not is_valid_rivergen_schema(task.data_source):
raise RiverGenAIError("ERR_INVALID_SPATIAL_SCHEMA")
# Persistent task registration
intent = TaskIntent(
project_ref="rg-core",
version="1.0.2",
ml_task=task.ml_task,
status="validated"
)
db.add(intent)
db.commit()
return {"task_id": intent.id, "status": "validated"}
2. AutoML Intelligence Engine
Source Path: app/services/automl_service.py
The engine is responsible for the actual "learning" phase. It uses a proprietary Meta-Learner to evaluate multiple algorithms in parallel.
The engine doesn't just train one model; it trains an ensemble and selects the one with the highest Stability Score (a composite of accuracy, latency, and drift resistance).
Training Orchestration Flow
The following sequence diagram outlines the high-level orchestration across disparate services when a training job is executed.
Intelligence Pipeline Stages
The Model Studio pipeline is divided into six distinct phases, each yielding a verifiable checkpoint.
Phase 1: Spatial Ingestion
Consumes telemetry directly from DIA stream buffers. Supports high-throughput SQL extracts and S3-based Parquet lakes.
Phase 2: Feature Alignment
Aligns disparate data sources into a unified feature vector. This stage handles timestamp synchronization and multi-agent coordination.
Phase 3: Adaptive Preprocessing
Handles "Unseen Categoricals" automatically by mapping platform agent states to a standardized latent space.
def adaptive_scaling(df, spatial_cols):
"""
Applies Standard Scaling with a fallback for out-of-bounds
geographic coordinates in RiverGen segments.
"""
scaler = RiverGenScaler()
df[spatial_cols] = scaler.fit_transform(df[spatial_cols])
return df, scaler
Phase 4: Logic Selection
Dynamically selects the best mathematical logic (Standard Regression, Bayesian Networks, or Neural Nets) based on the dimensionality of the feature space.
Phase 5: Accelerated Training
Utilizes CUDA-enabled agents for high-throughput spatial training when hardware acceleration is detected.
Phase 6: Lock & Register
The final model artifact is "Locked" (serialized) and registered with the Model Registry, along with a unique SHA-256 hash for integrity verification.
Data Schema (v1.0.2)
All AI-related metadata is stored in the RiverGen Core Database using the following schema:
Performance Optimization
To maintain sub-20ms inference latency across the project, the implementation utilizes:
- Selective Model Caching: Frequently accessed intelligence models are cached in the Redis Intelligence Layer.
- Asynchronous Dispatch: Training jobs are offloaded to background workers (Celery/RabbitMQ), freeing up the API for live request handling.
- Hardware Acceleration: Automatic detection of CUDA-enabled agents for high-throughput spatial training.
Infrastructure Security
- Isolation: Training jobs execute in isolated containers with limited filesystem access.
- Data Encryption: All artifacts stored in S3 or local FS are encrypted with AES-256-GCM.
- mTLS: Every internal communication between Model Studio and DIA requires mutual TLS certificate authentication.
Models are stored in a hierarchical structure: models/{version}/{task_id}/{model_id}/. This allows for seamless rollback and A/B testing support.
Technical Documentation - RiverGen Core Team - Last Updated: Jan 2026